Abstract
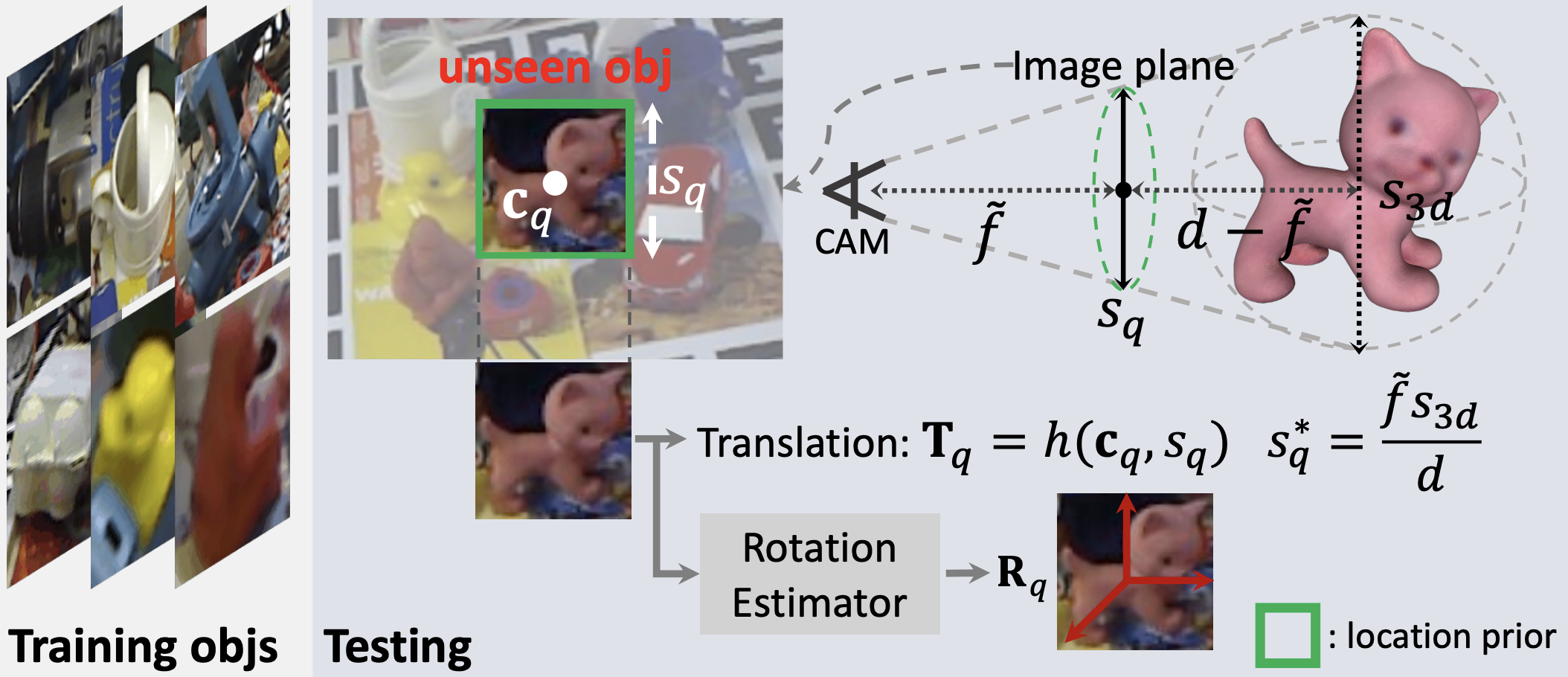 Object location prior can be used to initialize the 3D object translation and facilitate 3D object rotation estimation. The object detectors that are used for this purpose do not generalize to unseen objects. Therefore, existing 6D pose estimation methods for unseen objects either assume the ground-truth object location to be known or yield inaccurate results when it is unavailable. We address this problem by developing a method, LocPoseNet, able to robustly learn location prior for unseen objects. Our method builds upon a template matching strategy, where we propose to distribute the reference kernels and convolve them with a query to efficiently compute multi-scale correlations. We then introduce a novel translation estimator, which decouples scale-aware and scale-robust features to predict different object location parameters.
Object location prior can be used to initialize the 3D object translation and facilitate 3D object rotation estimation. The object detectors that are used for this purpose do not generalize to unseen objects. Therefore, existing 6D pose estimation methods for unseen objects either assume the ground-truth object location to be known or yield inaccurate results when it is unavailable. We address this problem by developing a method, LocPoseNet, able to robustly learn location prior for unseen objects. Our method builds upon a template matching strategy, where we propose to distribute the reference kernels and convolve them with a query to efficiently compute multi-scale correlations. We then introduce a novel translation estimator, which decouples scale-aware and scale-robust features to predict different object location parameters.
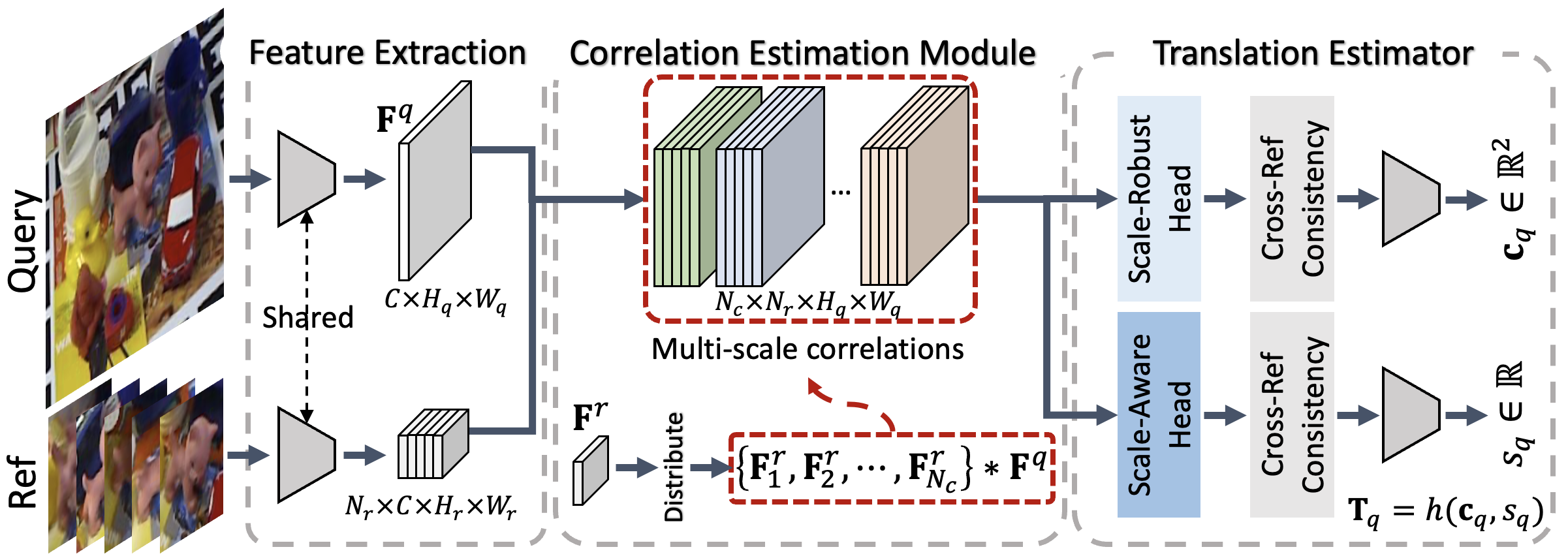 We explicitly separate the scale-related features, such as the multi-scale correlations, into scale-robust and scale-aware components. We predict the object center and the size from the scale-robust features and scale-aware ones, respectively, leveraging the consistencies across neighboring references. We introduce a computationally-friendly approach to extract the scale-related features, which bypasses the need for multiple forward passes through the backbone. This is achieved by leveraging the fact that the receptive field of the reference-query convolution is related to the size of a reference kernel. Thus, we estimate multi-scale correlations by distributing the reference kernels in different manners in the convolution process.
We explicitly separate the scale-related features, such as the multi-scale correlations, into scale-robust and scale-aware components. We predict the object center and the size from the scale-robust features and scale-aware ones, respectively, leveraging the consistencies across neighboring references. We introduce a computationally-friendly approach to extract the scale-related features, which bypasses the need for multiple forward passes through the backbone. This is achieved by leveraging the fact that the receptive field of the reference-query convolution is related to the size of a reference kernel. Thus, we estimate multi-scale correlations by distributing the reference kernels in different manners in the convolution process.

